Are you interested in languages and meeting people from other countries? Language exchange can be the best place to do so! Here you meet new friends, discover other cultures, practice your favorite language, and help others who are learning your language!

Most of these meetings are organized at regular intervals by volunteers. One of the most time-consuming tasks is to organize the learning groups. To support these dedicated volunteers I developed an optimizer that can organize the groups on its own. This could save a lot of working time.
Random Optimizer
During the last weeks, I had not much time, and so I wanted an optimization method that leads fast to the first results without thinking much about the formula. Plus I wanted to know how random optimizers perform under real-life conditions. For this purpose, I chose a random optimizer.
SPOILER-ALARM: there is no guarantee a random optimizer will find the optimal solution to a given problem. So this prototype should mainly deliver benchmarks for upcoming optimizers.
Optimization Process
Our random optimizer should maximize the number of participants in a language exchange event. For this, we will input the language exchange registrations into the program. Based on the participants it will organize groups so that every participant learns in a 2-hour event at least 1 hour. Preferably he should also teach for 1 hour his own language. I also added the following constraints:
- Each group needs at least 1 native/advanced teacher
- In each group, only 1-3 students are allowed
- Participants have to be busy for 2 hours
- No participant should teach 2 hours
If a participant is not assigned, he will be denied for this event.
Code
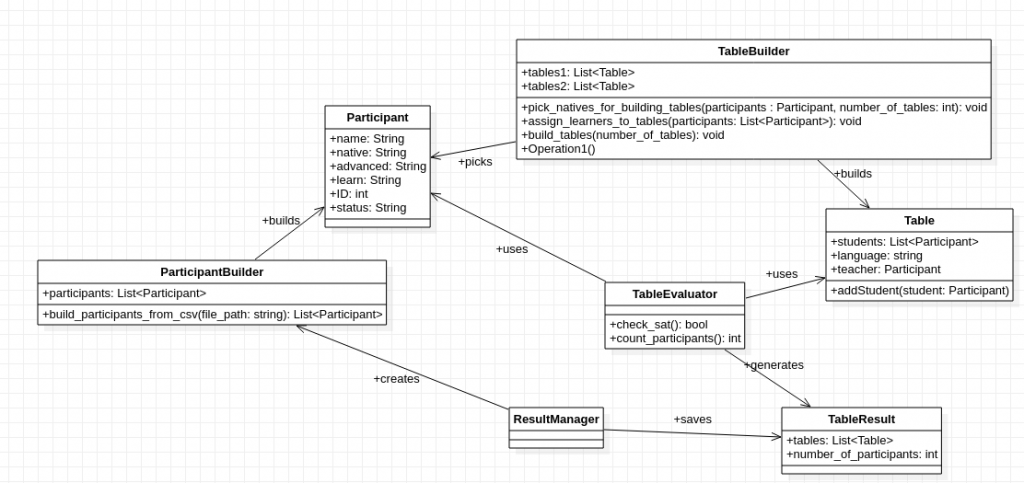
You can find like always the code and a dummy registration file in my GitHub-Repository. In the following picture, you can see the overall UML-diagram of the project. The ResultManager uses the ParticipantBuilder to build participants from the registration file. The TableBuilder builds tables and assigns participants to these tables. The TableEvaluator evaluates the TableBuilder result and saves it. The ResultManager takes care of the best generate result. The random optimization occurs while building the tables and assigning the participants to the tables. The overall process stops after 1000 iterations.
Results
Random Optimization is a method to develop models very fast. This helps us to understand the overall problem much more in detail. When we run this random optimizer on a registration file with 29 participants, it produces an average result with 12 participants (10 times 1000 iterations). This is actually a quite poor result, but now we have got a benchmark for other algorithms, which I will implement as soon I have got more time. So check out my next posts!