Barrier-free websites are like digital superheroes, battling against the evil of discrimination and exclusion by empowering everyone to engage with the digital world with ease and confidence, regardless of ability or disability. These websites aim to accommodate individuals with various disabilities, including visual impairments, hearing impairments, motor impairments, cognitive impairments, and seizure disorders.
With the integration of newer versions of language models like the Prometheus model (a successor of ChatGPT) into the Microsoft Edge web browser, website accessibility for language models will play a crucial role in the future. The ability to summarize website content and answer questions about it will be a valuable tool for people with and without disabilities, may influence how likely they visit a website, and could even impact the ranking of websites in search engines.
As a result, the optimization of website accessibility for language models will become an important aspect of future search engine optimization (SEO). This could involve adjusting website content and language to give the best output for language models, leading to higher search engine rankings and a better user experience for everyone.
The Fermi Quiz is a powerful tool for making accurate estimates and solving problems quickly. Named after physicist Enrico Fermi, this method involves breaking a problem down into smaller, more manageable pieces and using your knowledge and experience to make educated guesses. By following a few simple steps, you can use the Fermi Quiz to solve problems ranging from estimating the number of coffee shops in a city to calculating the number of stars in the universe. In this post, I will explain how to use the Fermi Quiz to make accurate estimates and demonstrate how ChatGPT, a chatbot, can help us generate more manageable pieces for our estimates and may even improve them.
Fermi Quiz
The Fermi Quiz is a method of solving problems and making estimates by breaking a problem down into smaller, more manageable pieces and using your knowledge and experience to make educated guesses. Here’s how it works:
Define the scope of your estimate: First, you need to clearly define the problem or question that you are trying to solve. This will help you focus your efforts and make it easier to come up with a good estimate. For example:How many bike stores are in the Netherlands?
Once you have defined the scope of your estimate, you can begin to break the problem down into smaller, more manageable pieces that help you answer the overall question independently. For example: 1. Piece: How many bike stores are in a dutch city on average? How many cities are in the Netherlands? 2. Piece: How many people in the Netherlands go on average in one week to a bike store? How many people can one bike store handle in a week? 3. Piece: How many bikes are in the Netherlands? How many bikes have an average bike store sold since its initial opening?
Answer all questions and estimate the actual value for the overall question with each piece independently. Average all of the estimates together to get the final estimate. This method is based on the wisdom-of-crowds effect, which states that averaging independent judgments often leads to improved accuracy.
ChatGPT for manageable piece generation
As a rule of dumb, more manageable pieces make your final result more precise. However, at some point, it can be difficult to generate more pieces. Therefore, we can utilize the chatbot ChatGPT to do it for us. You can use the following messages to generate the pieces via ChatGPT (note that the ChatGPT outputs vary, so you may have to tweak the messages a bit):
Estimate how many bike stores are in the Netherlands by using the Fermi quiz method and do not give me estimates.
[ChatGPT ANSWER]
What are five examples of breaking the problem down into smaller, more manageable pieces that I mentioned in my previous response?
[MULTIPLE IDEAS] (Piece 2 and Piece 3 were actually created by ChatGPT)
Estimate each generated manageable piece a value and average it with your previous estimated values.
Why did I not want to get an estimate from ChatGPT yet?
Estimate how many bike stores are in the Netherlands by using the Fermi quiz method and do not give me estimates.
The anchoring effect is a cognitive bias that refers to the tendency for people to rely too heavily on the first piece of information they receive (the “anchor”) when making decisions or judgments. This can lead to distorted judgments and decisions, as people may give too much weight to the initial anchor and not consider other relevant information. Therefore, knowing the estimate of the chatGPT (which is not necessarily precise) may influence your estimate.
Can ChatGPT improve our forecasting?
Now for every manageable piece, we use ChatGPT to get some estimates. Note that multiple times, the same question results in different estimates. This is not a big problem and we can handle it by, for example, averaging the estimates for each subquestion.
Let’s calculate the ChatGPT estimates.
1. Piece
How many bike stores are in a dutch municipality on average? How many cities are in the Netherlands?
Estimate via the Fermi quiz method how many bike stores are in a dutch municipality on average? -> ANWSERS: 5
Estimate via the Fermi quiz method how many municipalities are in the Netherlands. -> ANWSER: 233
ESTIMATE: 5 * 233 = 1165
2. Piece
How many people in the Netherlands go on average in one week to a bike store? -> 525000 How many people can one bike store handle in a week? -> 500
ESTIMATE: 525000/500=1050
3. Piece
How many bikes are in the Netherlands? -> 35 million bikes How many bikes have an average bike store in the Netherlands sold in its life span? -> 10000 bikes
ESTIMATE: 35,000,000/10,000 = 3500
FINAL CHATGPT ESTIMATE: (1165 + 1050 + 3500)/3 = 1905
Now that we have generated additional pieces using ChatGPT, we can average its estimate with your own to create a more precise estimate for the problem. To see how accurate your final estimate is, you can compare it to the actual number of bike stores in the Netherlands, which was approximately 3080 in 2020.
If you have tried using ChatGPT to generate additional manageable pieces for the Fermi Quiz method, please let me know in the comments how it worked for you. Did it help you come up with a more accurate estimate? Did combining your own estimate with ChatGPT’s estimate bring you closer to the actual number? I would love to hear your thoughts and experiences with using ChatGPT to improve the accuracy of your Fermi Quiz estimates. Please share your comments below.
Slaughterbots is a video that presents a dramatized near-future scenario where swarms of inexpensive microdrones use artificial intelligence, explosives, and facial recognition to assassinate political opponents by crashing into them. In my opinion, it is one of the most dystopian and depressing near-future scenario that I know.
When I watched the video the first time in 2017, I had no idea how we could defend towns against such terror attacks. Shooting against so many microdrones does not make sense. It also makes no sense to block the radio signals because the microdrones fly totally autonomous. Now, some years later, I realized that we could use secure machine learning to defend security-critical areas like shopping malls or train stations.
Many practical machine learning systems, like self-driving cars, are operating in the physical world. By adding adversarial stickers (patches) on top of, e.g., traffic signs, self-driving cars get fooled by these stickers.
Patch attacks projected on monitors in hallways, train stations, and so on could fool facial recognization systems on such suicide bombers. In this scenario, it is important to iterate over a lot of pretested patch attacks on test classifiers to find a potential weakness in the mini drones. After an effective attack was found, we could project this successful attack on all available screens in the attacked area.
When we imagine that nowadays shopping malls have physical barriers against terrorist truck attacks, nuclear underground utilities, and explosives in Swiss bridges it is not hard to imagine that we could develop an emergency program for public available monitors which could help defense against adversarial Slaughterbot attacks.
Problems of Generating Real-World Patch Attacks
Of course, there are still some problems left for generating real-world patch attacks. Images of the same objects, for example, are in real-world conditions unlikely exactly the same. To successfully realize physical attacks, attackers need to find image patches that are independent of the exact imaging condition, such as changes in pose and lighting. For that, we need to find adversarial patches that generalize beyond a single image. To enhance the generality of the patch, we look for patches that can cause any image in a set of inputs to be misclassified. For that reason, we formalize the generation of real-world patch attack as an optimization problem.
To find a quite universal patch for a certain classifier, it is important that we solved the optimisation problem for a lot of different classifiers before the actual attack.
In a world where machines are increasingly replacing the employment of people, we have to create new lifestyles. Passive income is an excellent way to earn money in such a world. It is derived from a rental property, limited partnership, or another enterprise in which a person is not actively involved. Nowadays, these organizations are mostly managed by public corporations. But soon, more and more autonomous organizations will arise because of the rapid development of artificial intelligence and the blockchain technology.
Based on this development, it could be possible to develop whole companies that work autonomously for people who don’t want to or can’t work anymore. So it could be a new business model for engineers to develop such companies for costumers.
But how could such an organization work internally?
Current neural networks can already evaluate the aesthetics of an image, so it will not take long until neural networks can also evaluate the appeal, usefulness, and other factors of a product. A combination of
Optimization Algorithms
Artificial Intelligence
Simulations
APIs to marketplaces like Amazon
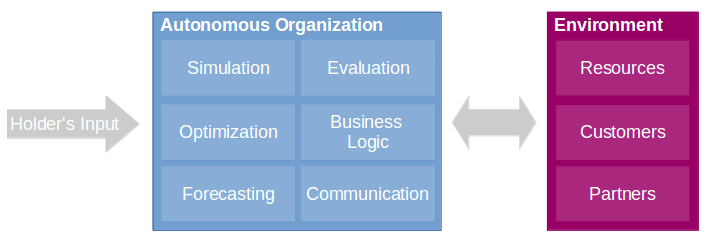
could be enough to run such organizations autonomously. Figure 1 illustrates an Autonomous Organization Framework. The holder inputs a number of assets and configures what the autonomous organization should do. The AO calibrates itself; then, it interfaces with Google Trends to analyze markets. Its analysis could find out that it is currently a profitable moment to sell remote-controlled cars. It could then use social media platforms to find popular models, and search other websites for the toy construction plans. After that, it could access online shops to extract the needed components, simulating many different combinations (optimizing via evolutionary algorithms, evaluating the product via deep learning and, finally, forecasting) to build a competitive RC-car. After constructing the product, it could be sold via the Amazon API.
Figure 1: A Framework for an autonomous organization
Besides such manufactory organizations, it would be probably easier to implement services like e-learning schools first. For example, an online school that teaches costumers how to dance salsa or bachata. From one of my previous posts, you already know how easy it is to develop a neural network that can differentiate between-song genres. It would also be possible to develop a classifier that can be detected if a person is dancing salsa or not.
I really prefer to have especially in social environments people instead of machines in control. But what is with my previous post about language table organizations? It would be much work to automate every single step of such an organization, but it could still be possible.
* This whole framework is for now just a general idea. Such organizations work probably better in a field where the competitive environment is not changing too much.
Around five years ago, Amazon released its smart assistant named Amazon Alexa. She has gained a lot of popularity among voice assistants. Most users use her to play music and search the internet for information. But these are just fun tasks. Alexa can help you with more of the daily tasks and make your life easier.
Amazon Alexa tries to be your assistant, but someone who reacts to commands doesn’t show any interpersonal relationship. This type of connection is essential for an assistant job – it builds respect and lets us see assistants like ‘individuals.’ This is one goal that AI developers want to achieve: Artificial Intelligence that is human-like. In this blog post, I want to discuss one possibility of achieving this goal.
Building an Interpersonal Relationship with Storytelling
A while ago, I read “Story” by Robert McKee. This book inspired me to think about human-like AI development a little bit differently.
Robert McKee describes in his books that a story is a metaphor for life – stories awaken feelings. When we watch good movies, we try to adopt the personal perspective of the movie characters. This leads to an ever-stronger bond with the characters in the course of the story.
This is exactly something that we want to achieve for our users and the virtual assistants. The field of storytelling reminds us that there is no way to love or hate a person if you have not heard that person’s story; that’s why our virtual assistant needs to have a backstory. As shown in the movie example, it makes no difference whether the person is real or not.
Often, a connection with movie characters arises when they make decisions in stressful situations. The real genius of a person manifests itself in the choices they make under pressure. The higher the pressure, the more the decision reflects the innermost nature of the figure. Stressful situations often appear for virtual assistants, such as when users ask for unanswerable questions. In this situation, ordinary virtual assistants answer with standard answers like, “I don’t understand,” or “I can’t help you.” In this case, the real character of the virtual assistant is revealed. AI developers have to avoid such standard answers, and instead, the artificial intelligence should answer such problematic user-questions with a backstory. The backstory depends on the use case but should be created by somebody familiar with storytelling and dialog writing. For dialog writing, I can recommend another book from Robert McKee called “DIALOG.”
According to the dramatist Jean Anouilh, fiction gives life a form. Thus, stories support the development of artificial life, making virtual assistants more than just empty shells.